2023年第4周 (01-23 ~ 01-29)
“大多数人并不关心人工智能研究。他们关心的是他们能否使用人工智能。” —— Sparrow VS ChatGPT
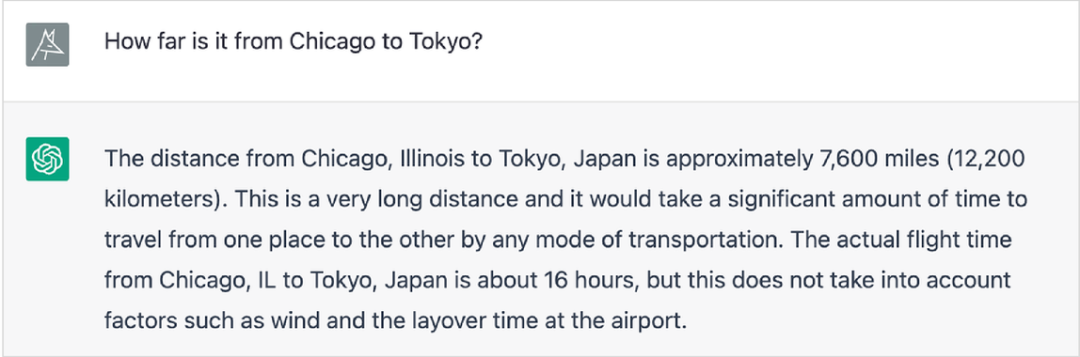
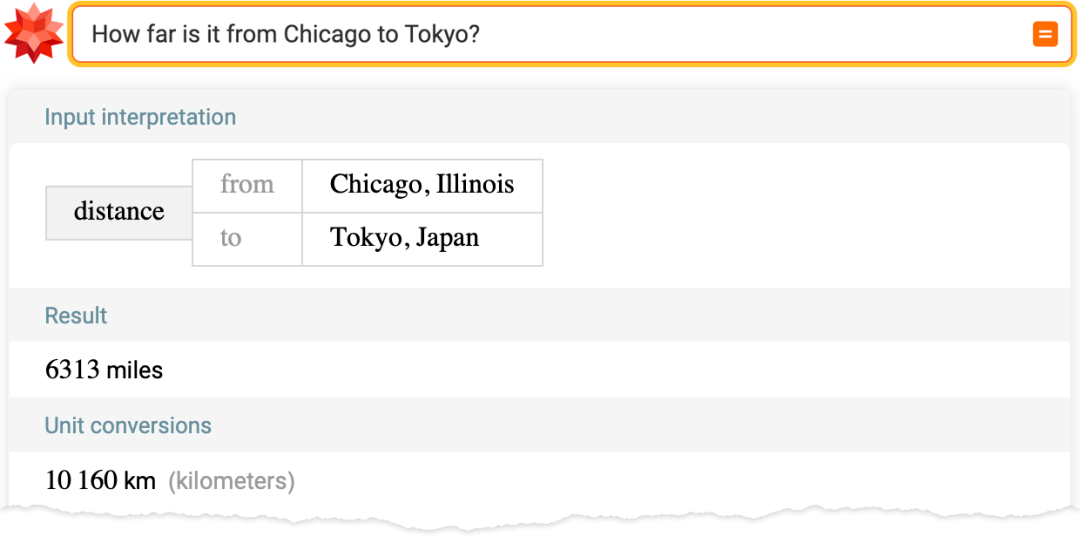
WolframAlpha 和 ChatGPT 实现互补
用 WolframAlpha 补足ChatGTP的数学(精确计算)短板。
ChatGPT 生成的是“统计上可信的” 随机答案,其回答数学这类问题,语言上看似有道理,而答案很可能是错误。
而这正是 Wolfram|Alpha 知识引擎擅长的事情:充分利用其结构化、高精准的知识将某事转化为精确计算。
两者的构建基础不同,ChatGPT 这类大语言模型使用 “统计方法”,Wolfram|Alpha 是基于 “符号方法”。
文本到图像的合成,GANs方法被抛弃了吗
文本到图像的合成方面,生成式AI模型(例如 DALL·E, StableDiffusion等)风头正劲。
本月23号谷歌发布了一篇论文 StyleGAN-T: 释放GANs的力量,实现快速的大规模文本到图像的合成,说到 StyleGAN-T 在样本质量和速度方面比以前的GANs有明显的改进,并超过了蒸馏扩散模型(outperforms distilled diffusion models)。
Jim Fan :(生成的图像)质量目前仍落后于大的扩散模型,但GANs正在进行反击!

ORBIT,机器人的“大数据”训练
@DrJimFan: 数据是新的石油。但物理世界的速度太慢,机器人无法收集大量的训练数据。所以我们就在模拟环境中,把速度提高1000倍。🔗
@NVIDIAAI 介绍了IsaacSim上的ORBIT,这是一个由GPU驱动的虚拟训练馆,供机器人“锻炼身体”。ORBIT还提供了与外围设备如键盘和3D “Spacemouse “的集成,以收集人类的演示。然后简单地运行监督学习来模仿人类的专家策略。
最后,将训练好的神经网部署到现实世界里的机器人种。
文本到音乐的生成,来自谷歌的新模型 MusicLM
原文: TechCruch的英文报道, 机器之心的中文报道和论文解读, MusicLM项目主页
@机器之心: MusicLM 不是第一个生成歌曲的 AI 系统。其他更早的尝试包括 Riffusion,这是一种通过可视化来创作音乐的 AI,以及 Dance Diffusion,谷歌自己也发布过 AudioML,OpenAI 则推出过 Jukebox。
虽然生成音乐的 AI 系统早已被开发出来,但由于技术限制和训练数据有限,还没有人能够创作出曲子特别复杂或保真度特别高的歌曲。不过,MusicLM 可能是第一个做到的。
更多新闻
- (2023-01-25) 生物医学研究平台Terra现可在微软Azure上使用