2023年第5周 (01-30 ~ 02-05)
闲言:AIGC 蓬勃发展,AI对创作性工作的冲击来得如此迅猛。文本、图像、人声、音乐、视频的生成都已逐步进展到可以融入日常工作生活的实用阶段。模型和产品层出不穷。
你唱歌,AI给你伴奏
谷歌推出 SingSong 模型,可以根据唱歌的人声,生成合适的配乐。巧妙的使用了已有的人声和背景音乐分离的模型,对大量的音乐语料进行分离,获得大量的人声-音乐音频训练数据,再反过来训练 SingSong 模型。
(视频来源)
最近有多个文本到音频的模型发布:
- AudioLDM: Text-to-Audio Generation with Latent Diffusion Models
- Moûsai: Text-to-Music Generation with Long-Context Latent Diffusion
- Google MusicLM: Generating Music From Text
音乐生成模型才刚刚开始
DrJimFan:最新的音乐模型仍然缺乏人类作曲家的长期连贯性和全局结构。如果用图像模型来类比,大致相当于DALL-E v1的技能水平。但我们会在 2023 年看到 MidJourney 级别的真正有能力的 AI 音乐家吗?
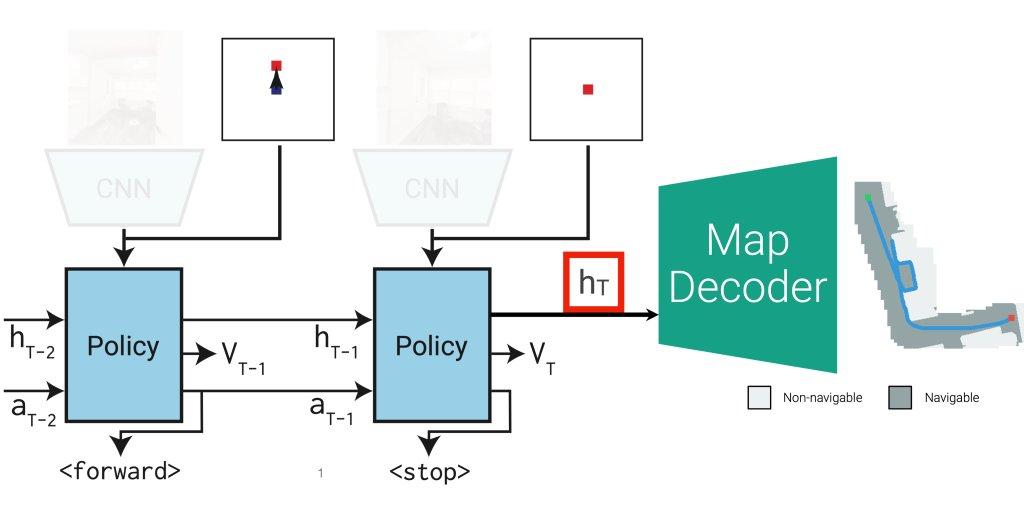
AI模仿盲人实现“无地图”导航代理
人类有能力依靠触觉和记忆来导航光线不足的空间。@MetaAI 发表新论文,其训练盲人 AI 代理进行导航——即除了自我运动之外没有任何感官输入,并在他们的记忆中发现了墙面跟随、碰撞检测神经元和类似地图的表征。 这为“无地图”导航代理的成功提供了新的见解。
大脑回放机制的研究帮助我们深度学习与推理的结合
@DeepMind: 我们大脑中的重放被比作人工智能代理的 “经验重放”。🔁 🧠
但新的研究表明,这种现象在计算上比我们想象的更丰富–而且可以帮助我们理解大脑如何将深度学习与推理结合起来。
论文:Replay and compositional computation
Dreamix 一款视频生成模型
论文 Dreamix: Video Diffusion Models are General Video Editors
项目主页 https://dreamix-video-editing.github.io/
谷歌与 AnthropicAI 合作,类似微软与 OpenAI 的合作模式
AnthropicAI 发布公告 与 Google Cloud 成为合作伙伴。或类似 Microsoft Azure 与 OpenAI 的合作模式:投资初创公司去拓展AI前沿应用,同时为了自家的云计算服务在AI训练领域夯实基础。
2021年,Anthropic成立,创始人Dario Amodei来自于OpenAI,据FT报道,当时Dario Amodei领导的研究小组,在和公司的方向产生分歧后离开了OpenAI,Anthropic更关注高级人工智能安全。而Anthropic开发了一款名为Claude的智能聊天机器人,据说能够与OpenAI的ChatGPT相媲美。——阿法兔研究笔记
相关新闻: