2023年第9周 (02-27 ~ 03-05)
人人都能使用AI很重要,否则加剧不平等。
 (Generated with StableDiffusion 1.5)
(Generated with StableDiffusion 1.5)
实践:用AI总结视频内容
以小Lin说的这期视频为例,是个很好的科普视频,回顾了ChatGPT和聊天机器人的历史,以及OpenAI、微软和谷歌在其中的角色和故事。
 (视频截图)
(视频截图)
以下是 ChatGPT 对视频内容的概括:
“视频介绍了Chat GPT,一个强大的聊天机器人,它具有强大的自然语言生成能力,可以编写脚本和小说,甚至参加医学和司法考试。该视频还探讨了聊天机器人的起源,机器学习的基本理念,神经网络的发展,以及OpenAI和微软的合作。视频还提到了大型语言模型的优缺点,需要对其使用谨慎并审慎考虑其输出。 Chat GPT 的突破在于它可以提高人类和机器之间的沟通效率,但也引发了一些问题,如可能导致谁失业等。”
具体方法和过程是:
- 首先用开源的AI模型Whisper(来自于OpenAI)+ 开源工具 autocut,将音频听录成字幕。
- 再人工将内容文本按篇章进行分段,让ChatGPT分别进行总结。
- 最后将所有分段总结合并在一起,再让ChatGPT做一次总结。
Whisper 和 ChatGPT 都是支持多语言的,所以也可以直接实现跨语言的内容总结。
OpenAI 上线 ChatGPT 和 Whisper API 服务
3月1日,OpenAI 推出 ChatGPT 和 Whisper API,使开发者能够将先进的文本对话和语音转文本能力,集成到他们的程序和产品中。
公布的 gpt-3.5-turbo 模型是和当前 ChatGPT 使用的相同模型。相较之前的 text-davinci-003 模型,成本下降了 10 倍! 调用 API 的计费价格也随之降低。
Whisper 是 OpenAI 开源的语音转文本模型,支持多语言(包括中文),效果很好。
这将进一步促进更多应用场景的出现。官方博文 中也演示了一些企业已使用新版API将 ChatGPT的能力融入到了自身的产品中,例如 Snapchat、Quizlet、Instacart等。
OpenAI 还根据开发者反馈调整了其 API 的服务条款,例如不再将通过API提交的数据用于训练 ChatGPT。
商业服务上,可提供专用实例(服务器),以便用户更好地控制特定模型版本和系统性能。
ControlNet,让AI按需绘图更进一步
之前使用稳定扩散模型来画图都是通过不断调整提示词来生成期望的图片。ControlNet 的出现让我们可以提供图片作为附加输入条件, 让Stable Diffusion等模型生成更接我们近期望的图片。
例如输入一张狗狗的照片,选择提取边缘轮廓,生成多张形态相似的狗狗图片: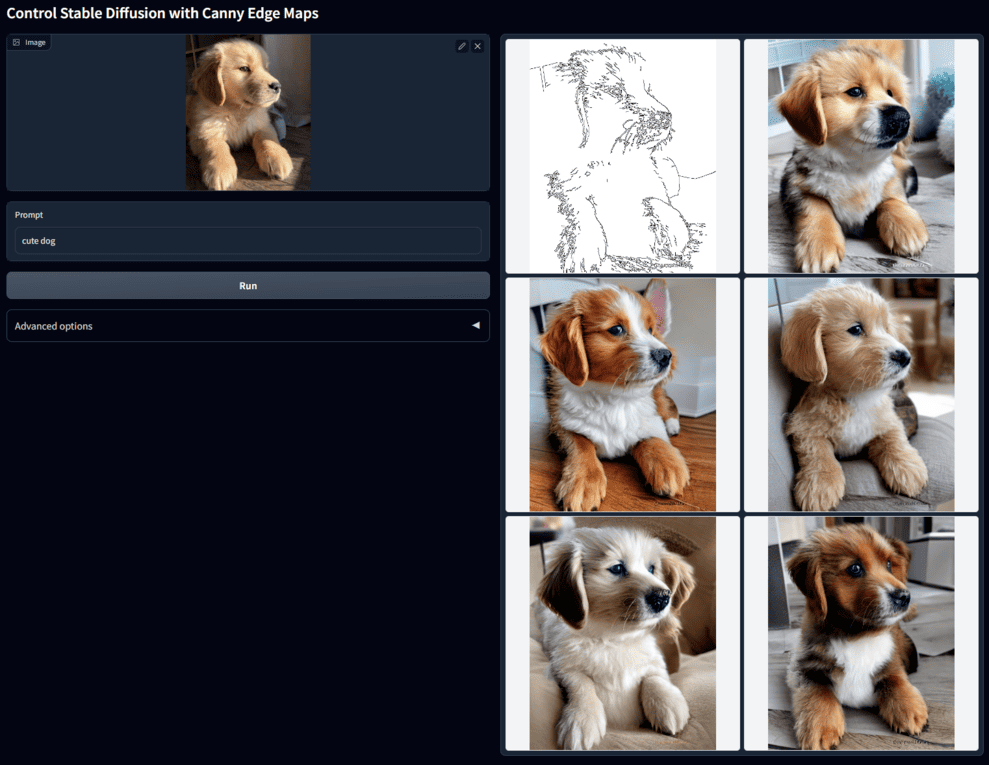
(图片来自该项目文档)
例如输入一张房屋室内照片,选择线段检测,+提示词,可以生成结构相似但风格不同的室内图: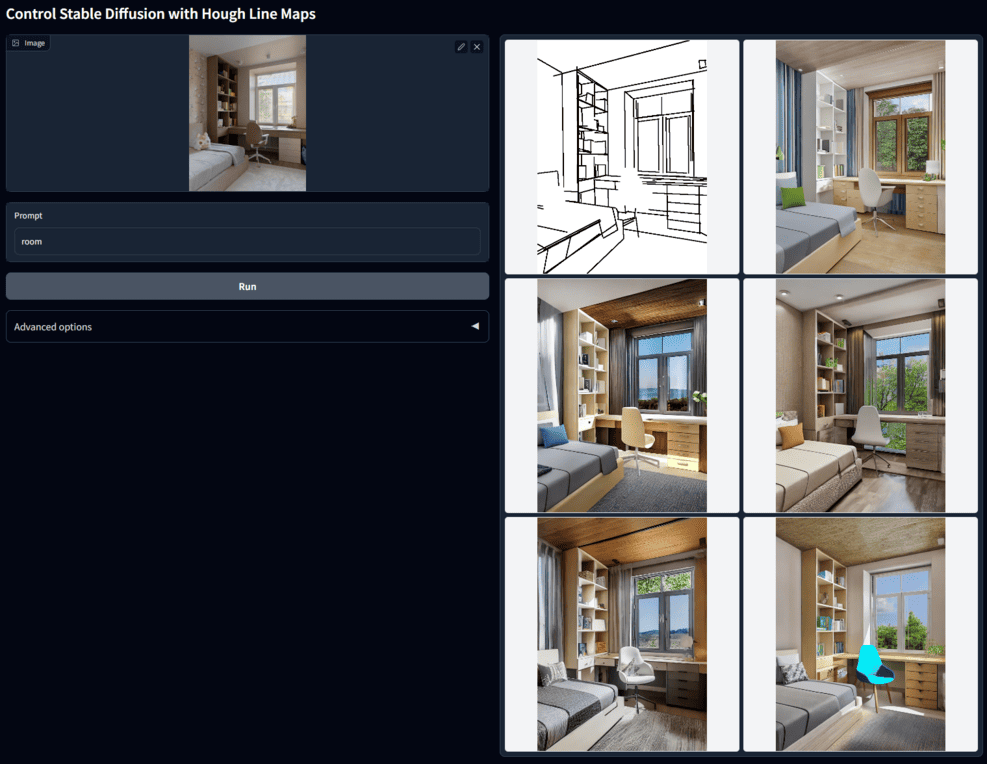
例如输入一张人脸,选择HED(嵌套边缘检测),绘制画风不同的相似人脸: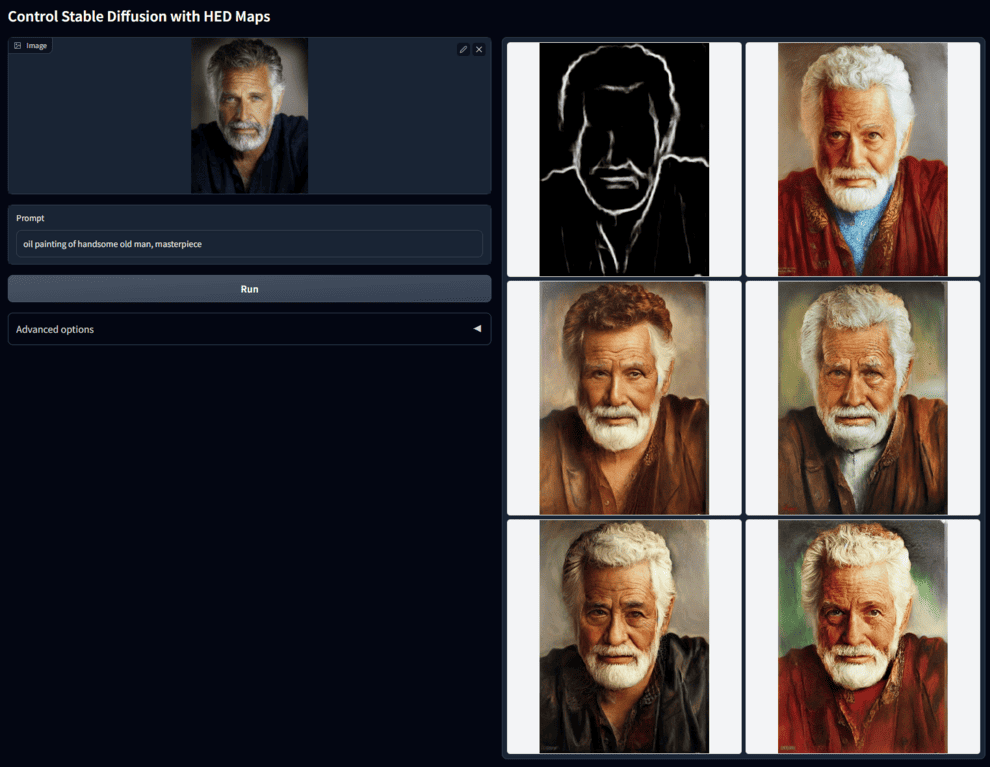
例如输入一张全身像照片,选择提取人体姿势,+提示词,生成姿态相同但场景和角色不同的图片: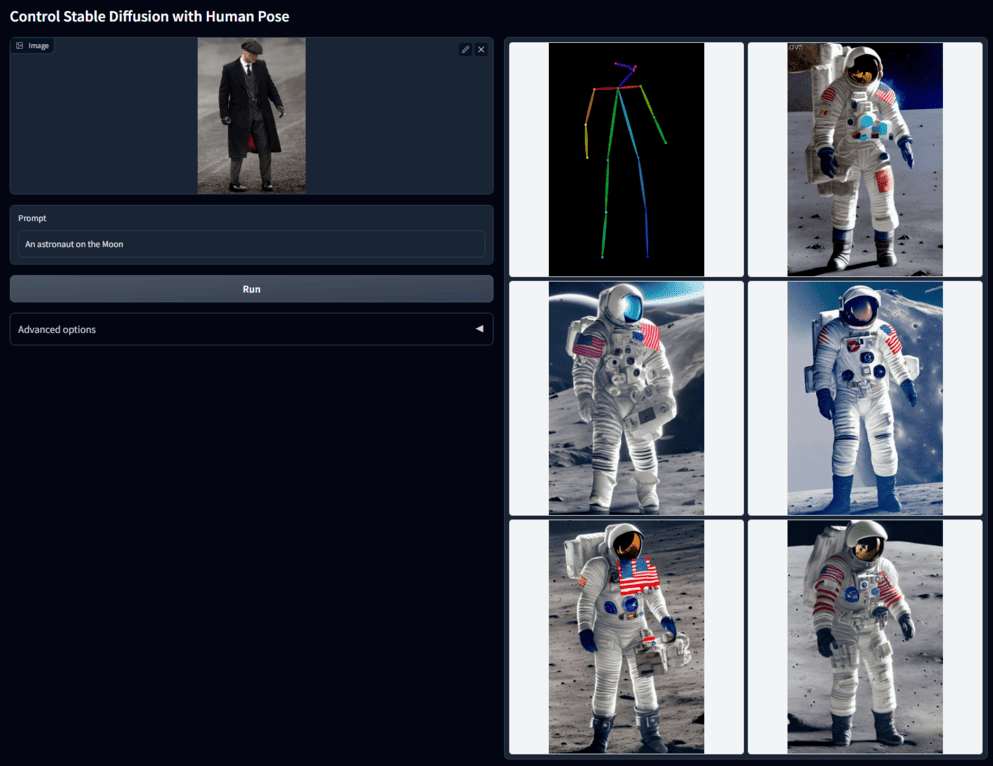
或者直接随手涂鸦,根据涂鸦线条+提示词绘制图片: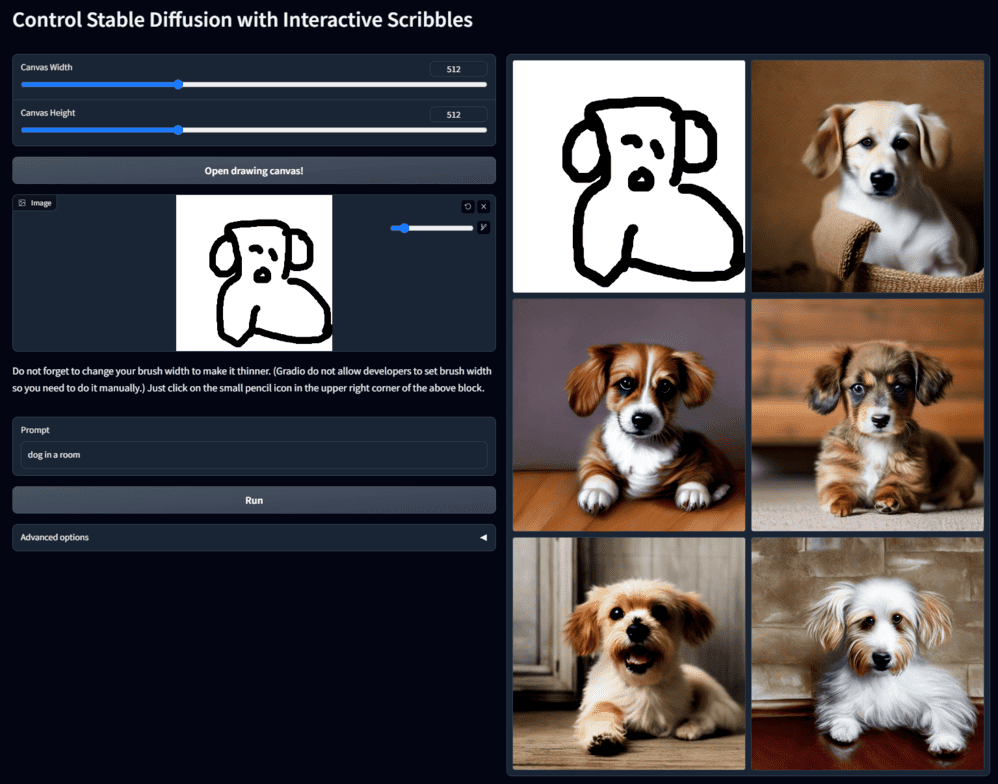
更多案例和说明可以参见官方项目主页/代码仓库,
以及论文 Adding Conditional Control to Text-to-Image Diffusion Model,
在线试玩 demo 1, demo2。
通过结合现有的图片信息提取方法,已支持条件有:边缘检测、线段检测、图像语义分割、人体姿势、人体关键点特征、深度图、涂鸦、草图线稿等。
ControlNet 丰富了控制大型扩散模型的方法,实用程度上了一个台阶,会进一步促进相关应用。
又是一波创造力与生产力的提升。例如拿小姐姐跳舞的视频逐帧生成图片之后合成了一个新的小姐姐跳舞视频。🐒
BLOOM,学术界协作并开源的大语言模型
人工智能的加速发展将对社会产生根本性影响。这项工作的很大一部分源于在更大的数据集上训练更大的模型。
这项努力的资源主要掌握在大型科技巨头手中。从研究进展、环境、伦理和社会的角度来看,对这种在变革性技术上的束缚会带来问题。
BigScience 项目从 CERN 和 LHC 大型科学项目中获得灵感,以开放的科学合作促进了对整个研究界有用的大规模人工制品的创造。旨在展示另一种在 AI/NLP 研究社区内创建、研究和共享大型语言模型和大型研究成果的方法。
以上内容摘录并翻译自 BigScience 项目主页
 (BLOOM项目横幅图)
(BLOOM项目横幅图)
BigScience 发布了 BLOOM 模型。这是第一个在完全透明的情况下接受过培训的多语言 LLM,其拥有 1760 亿个参数,能够生成 46 种自然语言和 13 种编程语言的文本。
这是来自 70 多个国家和 250 多个机构的 1000 多名研究人员一年的工作成果。法国研究机构 CNRS 和 GENCI 为该模型的训练资助了价值 300 万欧元的计算资源。
任何人现在都可以下载、运行和研究 BLOOM:模型文件和在线演示Demo
更多开源的模型和数据集,可访问托管在 HuggingFace 的资源页面
LAION-AI 的 Open-Assistant,做真正开放的对话AI
在 OpenAI 的 GPT-3 不再 Open 之时。 LAION-AI,一个非营利性组织,旨在将大规模机器学习模型、数据集及相关代码提供给公众使用。
其发起的项目 Open-Assistant,首先是对标/复刻 ChatGPT,做一个开源版的基于聊天的助手。更长远的目标是希望它能够理解任务,可以与第三方系统进行交互,并动态地检索信息以执行更多任务,并具有个性化和可扩展性,可以被任何人所使用。
 (open-assistant.io网站截图)
(open-assistant.io网站截图)
该项目以开源的大语言模型、开源数据集作为基础,并希望通过开放众包的方式来收集大量高质收集对话和指令的数据。
任何人都可以通过 open-assistant.io 网站,提交回复、分类回复或打分回复,直接帮助改善 Open Assistant 的能力。 这一过程类似 OpenAI 为 ChatGPT 花钱找外包团队标注数据。
微调训练 ChatGPT 的技术细节,可参考往期周刊内容:跟着李沐精读 InstructGPT 论文,以及下一条内容。
Open-Assistant 的模型、方法和数据集都是开源的。
解读 ChatGPT 背后的技术重点
Hugging Face 的博文 What Makes a Dialog Agent Useful?,
姚伟峰翻译的中文版:解读 ChatGPT 背后的技术重点:RLHF、IFT、CoT、红蓝对抗
预训练的大语言模型(LLM),例如 GPT-3、Bert 其训练方式是预测文本,并不会遵循指令。
ChatGPT 是如何对LLM做微调训练的呢?
第一步,使用 指令微调 (Instruction Fine-Tuning,IFT)的方法对基础模型进行微调。这些指令示范由三个主要部分组成 —— 指令、输入和输出。
经过指令微调的 LM 并不总是能生成 有帮助的 和 安全的 响应。
第二步,使用 有监督微调 (Supervised Fine-tuning, SFT),在高质量的人类标注数据上微调基础语言模型,以提高有用性和无害性。SFT 和 IFT 联系非常紧密。指令微调可以看作是有监督微调的一个子集。
第三步,使用 人类反馈强化学习 (Reinforcement Learning From Human Feedback,RLHF) 来微调模型生成符合人类偏好的回答。该方法根据人类反馈来对模型的响应进行排序标注,然后,用这些带标注的响应来训练偏好模型。
思维链 (Chain-of-thought,CoT) 提示,是指令示范的一种特殊情况,它通过引发对话代理的逐步推理来生成输出。使用 CoT 微调的模型在涉及常识、算术和符号推理的任务上表现得更好。
相关阅读:
- HuggingFace: Illustrating Reinforcement Learning from Human Feedback (RLHF) (中文版: RLHF 技术详解)
为什么目前还没有能够复现 ChatGPT 能力的其它产品?难度在哪里?
- 杨靖锋:Why did all of the public reproduction of GPT-3 fail?(中文版:为什么所有GPT-3复现都失败了?)
文中提及:基于谷歌开源的 FLAN-T5 模型,有可能微调出优于 ChatGPT 的聊天机器人。
一份关于人工智能的资讯摘录周刊,记录值得关注的AI产品、技术研究、项目进展、引人思考的观点和鼓舞人心的理念。注视正在发生的未来。