2023年第16周 (04-17 ~ 04-23)
大模型涌现出新能力、多模态的必然趋势和通用基础模型。
能力的涌现
扩大语言模型的规模已被证明可以可靠地提高泛化能力(即提高下游任务的性能和样本效率)。
Jason Wei 等人在2022年8月的一篇论文中论述了另一种不可预测的现象——大型语言模型能涌现出新的能力。论文中给出的定义是:如果一种能力在小型模型中不存在但会在大型模型中出现,则称其为是涌现出的能力。
因此,涌现能力不能简单地通过推断小模型的能力来进行预测。这种涌现出的能力的存在引发了一个问题,即是否可以通过进一步扩大语言模型的规模来进一步扩展语言模型的能力范围?
下图展示了在仅用少量样本作为提示的测试中,语言模型的尺寸在小于某个规模之前,其执行任务的表现是随机的。模型的参数量超过某个规模之后,回答的结果准确性大幅提高,明显高于随机的程度。
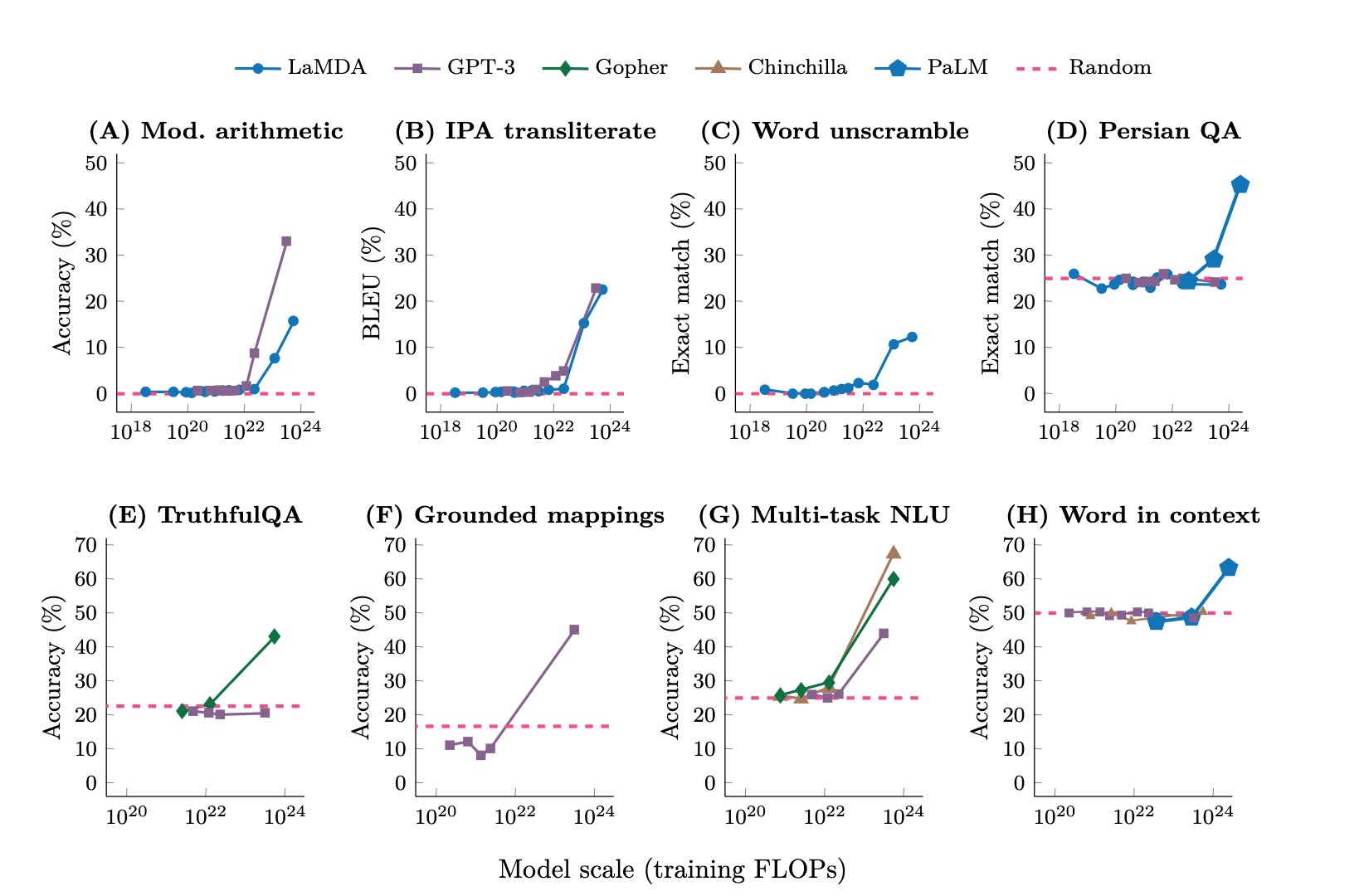
(图片取自 https://openreview.net/pdf?id=yzkSU5zdwD)
Jason Wei 在其博文中整理列出了 137 中大语言模型涌现出来的能力。
由于涌现是非线性的,这也使得要预测它的发展极为困难。如果今天的模型暂时还不能解决某一类任务,你无法估计模型要再扩张多少才能涌现出新的能力去解决这些任务。可能永远不行,可能下一个阈值会超出硬件的能力极限,可能你需要的全新的网络架构。所有这些问题都无法用简单的外推来回答。这种非线性或也是人工智能波浪形发展的根源:你会在好几年里觉得一事无成(比如前几年大量声音说大模型已死),接着忽然迎来一个剧烈爆发的增长,然后可能又进入下一个等待期。
(此段摘录/修改自 木遥的文章,2023年2月)
多模态
什么是多模态(Multimodal)?
多模态是指通过多种不同的感官模式(例如视觉、听觉、触觉等)进行信息的处理和表达。在计算机科学领域,多模态通常指的是使用多种不同的数据类型(例如图像、文本、音频、视频等)进行机器学习或人工智能任务。这些数据类型可以同时输入到同一个模型中,或者经过前期的处理后融合在一起,以提高模型的准确性和表现力。
2017年谷歌的研究团队在论文 One Model To Learn Them All 就提出了多模态架构。
其摘要中说到:从语音识别、图像分类到翻译,深度学习在许多领域都取得了很好的成果。但对于每个问题,要使深度模型良好运行,都需要对架构进行研究和长时间的调优。我们提出了一个单一模型,该模型在跨越多个领域的许多问题上产生了良好的结果。
2021年11月的谷歌的一篇博客文章 开篇就以翻译为例,说明了多模态的有效性:
对于许多概念,没有从一种语言到另一种语言的直接一对一翻译,即使有,这种翻译也常常带有不同的联想和内涵,非母语人士很容易忘记这些联想和内涵。然而,在这种情况下,当基于视觉示例时,含义可能会更加明显。以“婚礼”这个词为例。在英语中,人们通常会联想到穿着白色礼服的新娘和穿着燕尾服的新郎,但当翻译成印地语 (शादी) 时,更合适的联想可能是穿着鲜艳色彩的新娘和穿着 sherwani 的新郎。每个人对这个词的联想可能会有很大差异,但如果向他们展示预期概念的图像,其含义就会变得更加清晰。(摘录/翻译自谷歌博客)

(图片取自谷歌博客) 英语和印地语中的“婚礼”一词传达了不同的心理意象。
亚马逊研究团队2023年2月发表的一篇论文 中,分享了对多模态思维链推理能力的研究,也说明加上图片信息的处理,多模态,小语言模型就能实现很好的推理效果。摘要如下:
大型语言模型(LLMs)通过使用思维链(chain-of-thought, CoT)提示来生成中间推理链以推断答案,展现了在复杂推理方面惊人的性能。然而,现有的CoT研究仅关注于语言形式。我们提出了一种Multimodal-CoT方法,将语言(文本)和视觉(图像)模态纳入一个分离了理由生成和答案推断的两阶段框架中。这样,答案推断可以利用基于多模态信息生成的更好的理由。通过Multimodal-CoT,我们的模型在10亿参数以下的情况下,在ScienceQA基准测试中比之前的最先进LLM(GPT-3.5)高出16个百分点(75.17%->91.68%准确率),甚至超过人类表现。
下图展示给AI模型一幅图片,上面画着饼干和薯条,然后问 AI“这两者的共同点在哪里?”,提供两个答案选项“A:都是软的。B:都是咸的。”
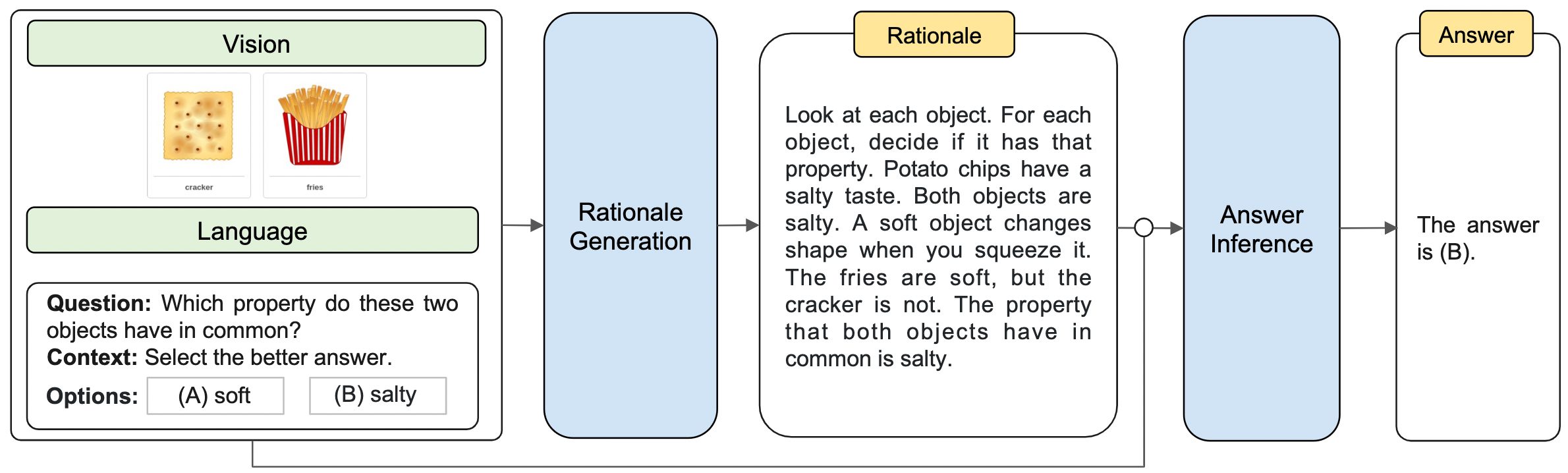
(图片取自 github@amazon-science/mm-cot)
2023年3月,谷歌发布的 PaLM-E 多模态大模型,展示了文本+视觉+机器人传感器数据的融合,打造通用型机器人的进展。
2023年3月,OpenAI 首席科学家 Ilya 和 Nvidia CEO 老黄在炉边对谈中也提到,
GPT-4 扩展到多模态有两个维度的因素,第一个维度是它有用的,
神经网络通过视觉模态可以更好地理解世界;因为世界是非常视觉的,人类是非常视觉化的动物,人类大脑皮层的三分之一是用于视觉的。
第二个维度则是可供学习的数据量。除了从文本中学习外,我们还可以通过从图像中学习来了解这个世界。
实际的效果是,在需要理解图表的测试中,GPT3.5 的正确率是2%~20%,多模态的GPT-4准确率提高到40%。视觉信息可以帮助我们更好地理解和推理世界,并有助于更好地进行视觉交流。未来的神经网络可能能够通过视觉方式来解释问题,而不仅仅是提供文本解释。
人的感知和智能天生就是多模态的,不会局限在文本或图像等单一的模态上。因此,多模态是未来一个重要的研究和应用方向。另外,由于大规模预训练模型的进展,AI 的研究呈现出大学科趋势,不同领域的范式、技术和模型也在趋近大一统。跨学科、跨领域的合作将更加容易和普遍,不同领域的研究进展也更容易相互推进,从而进一步促进人工智能领域的快速发展。
(此段摘录自 木遥的文章,2023年2月)
总结
(以下总结部分摘录/修改自 微软亚洲研究院文章,2022年8月)
近年来,基础模型(foundation models,也被称为预训练模型)的研究从技术层面逐渐趋向于大一统(the big convergence),不同人工智能领域(例如自然语言处理、计算机视觉、语音处理、多模态等)的基础模型从技术上都依赖三个方面:
一是 Transformers 成为不同领域和问题的通用神经网络架构和建模方式。模型架构的统一,为预训练的大一统提供了基础。
二是生成式预训练(generative pre-training)成为最重要的自监督学习方法和训练目标。基于掩码数据建模(masked data modeling)的预训练已成功应用于多种模态,如文本和图像。
三是数据和模型参数的规模化(scaling up)进一步释放基础模型的潜力。扩大模型规模和数据大小可提高基础模型的泛化能力,从而提升模型的下游迁移能力。
技术和模型的统一将会使得 AI 模型逐步标准化、规模化,从而为大范围产业化提供基础和可能。通过云部署和云端协作,AI 将有可能真正成为像水和电一样的“新基建”赋能各行各业,并进一步催生颠覆性的应用场景和商业模式。
文/图来源:
https://www.jasonwei.net/blog/emergence
https://openreview.net/pdf?id=yzkSU5zdwD
https://mp.weixin.qq.com/s/cFQBqjKEnqnT6NMUMRZN9A
https://arxiv.org/abs/1706.05137
https://www.msra.cn/zh-cn/news/features/beit-3
https://www.msra.cn/zh-cn/news/features/nuwa-xl
https://arxiv.org/abs/2302.00923
https://github.com/amazon-science/mm-cot
AI展望周刊,个人向的阅读摘录,关注AI、理解AI,注视正在发生的未来。
📡 全文RSS | 往期留存网页版
📰 推荐「AI资讯简报」一览每日AI新鲜资讯。