2023年第19周 (05-08 ~ 05-14)
大模型与医疗
安全问题
微软研究院的这篇访谈文章 提到:
将计算机技术整合到医疗健康和医学工作流程中的实际挑战,是要确保它的安全性,并且真正发挥计算机技术的最大能力,但这是非常困难的。
在医学实际应用中,诊断和治疗过程都发生在不稳定的环境中,这就导致在机器学习的环境中涉及很多混杂因素。由于医学是建立在对因果关系的精确理解和推理之上的,所以这些混杂因素至关重要,但现在机器学习里最好的工具本质上是相关性的机器(correlation machines)。相关性和因果关系是不同的,例如,吸烟是否会致癌,考虑到混杂因素的影响并了解其中存在的因果关系是非常重要的。
另一方面,我们不必完全专注于临床应用。GPT-4 很擅长填写表格,减轻文本工作的负担,它知道如何申请医保报销的事先授权,这是医生目前主要的行政和文本负担。相关工作并没有真正影响到攸关生死的诊断或治疗的决定。
GPT3/4 是第一个可以问它没有任何已知答案的问题的人工智能系统。而问题是,我们能完全相信它所给出的答案吗?
“负责任的人工智能”一直是整个计算机科学领域的重要研究课题,但我想这个词现在有可能不再合适了,我们可以称之为“社会性的人工智能(societal AI)”或其他的术语。
它不是正确与错误的问题,也不仅仅是它会被误用而产生有害的信息,而是在监管层面的更大的问题,还有在社会层面的工作流失,新的数字鸿沟,以及富人和穷人获得这些工具的权利。这些亟待解决的问题也会直接影响着它在医疗健康领域的应用。
能力问题
Google AI 的文章 提到:
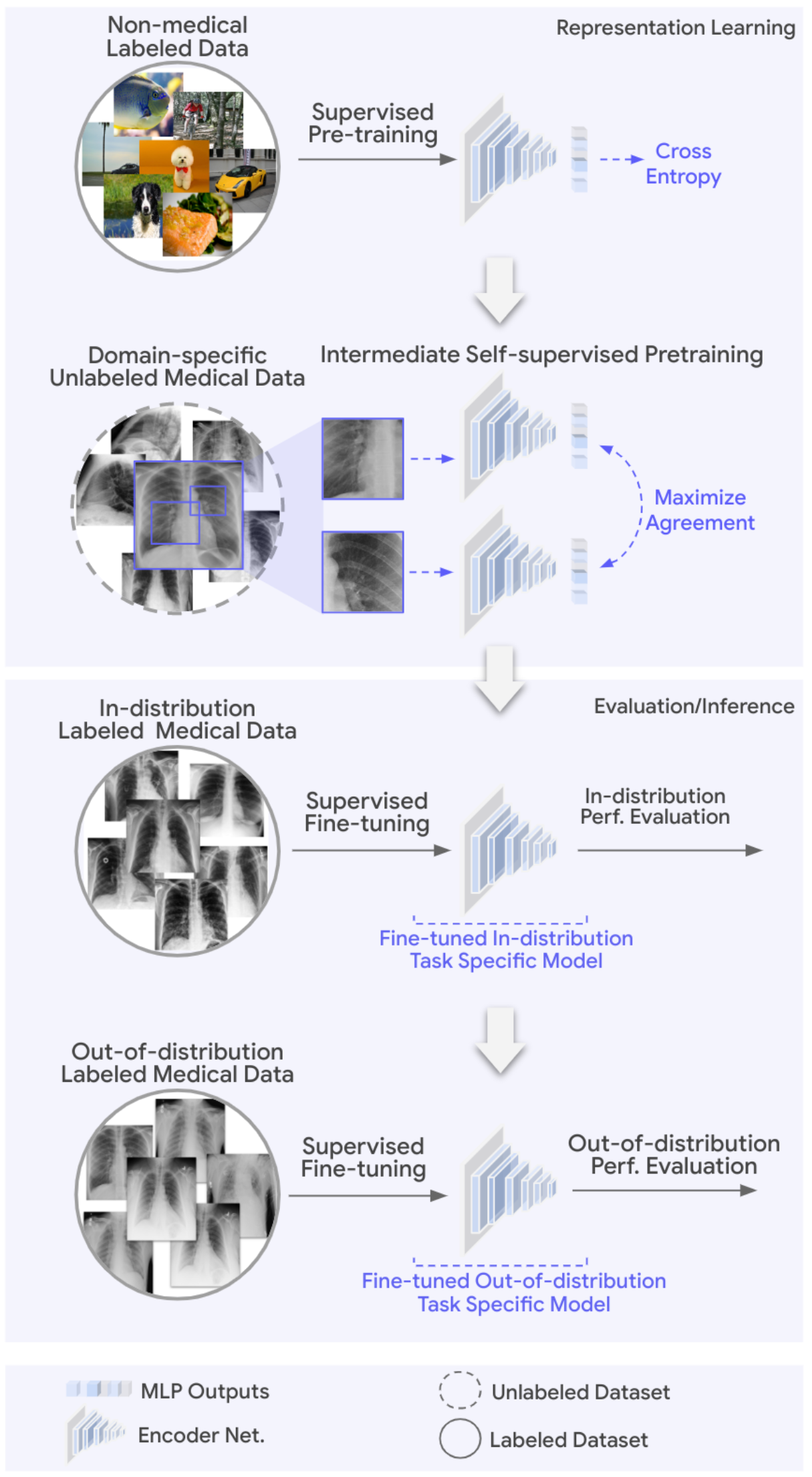
尽管最近在医学人工智能 (AI) 领域取得了进展,但大多数现有模型都是狭窄的单任务系统,需要大量标记数据进行训练。此外,这些模型不能轻易地在新的临床环境中重复使用,因为它们通常需要为每个新的部署环境收集、去识别和注释特定于站点的数据,这既费力又昂贵。数据高效泛化的问题(模型使用最少的新数据泛化到新设置的能力)仍然是医学机器学习 (ML) 模型的关键转化挑战,并反过来阻碍了它们在现实世界医疗保健环境中的广泛采用。
Google 研究团队提出了一种降低 AI 模型训练成本并提高泛化能力的思路和时间:

(图片取自 Google AI Blog)
Google REMEDIS 使用自然图像和未标记的医学图像相结合的方法,采用两步预训练策略进行大规模自监督学习,使用 SimCLR 方法训练模型学习医学数据表示,该方法避免了耗时、费用高的标注数据的过程。模型训练完成后,通过标记的任务特定医学数据对其进行微调,并使用少量的分布不同的数据进行评估,从而实现数据高效泛化。
(图片取自 Google AI Blog)
该研究评估了REMEDIS模型在多种医学成像任务和模态下的性能,相对于强监督基线模型在诊断准确性上有着高达11.5%的相对改进,并且可以实现医学成像模型的数据高效泛化,相当于减少了3-100倍的重新训练数据需求。同时,该方法适用于多种模型架构大小,并且与多种对比自监督学习方法兼容。
AI展望周刊,个人向的阅读摘录,关注AI、理解AI,注视正在发生的未来。