2023年第21周(05-22 ~ 05-28)
多模态任务联合训练实现更少参数更优表现
Google AI 提出了一种 多模态任务联合训练 的框架 MaMMUT 。以更简单的架构、更少的参数量实现媲美甚至超过单项大模型的能力表现。
(2023-05-04)
MaMMUT 是一种简单紧凑的视觉编码器-语言解码器(vision-encoder language-decoder)模型,2B 参数量。 它共同训练了许多相互冲突的目标,以调和 类似对比(contrastive-like)和 文本生成(text-generative)的任务。
由于它是针对这些不相交的任务进行训练的,因此它可以无缝地应用于多个应用程序,例如图像-文本和文本-图像检索、视觉问答(VQA) 和视频字幕(video captioning)和开放词汇检测(open-vocabulary detection),且优于现有一些大模型实现有竞争力的性能。
还可以更轻松适应视频语言任务。以前的方法使用视觉编码器单独处理每一帧,这需要多次应用视觉编码器,造成速度很慢,并且限制了模型可以处理的帧数,通常只有 6-8 帧。
使用 MaMMUT,使用稀疏视频管直接通过视频中的时空信息进行轻量级适应,只需要执行一次视觉编码器。
第23周(06-05 ~ 06-11)
AI写出了更快的算法程序
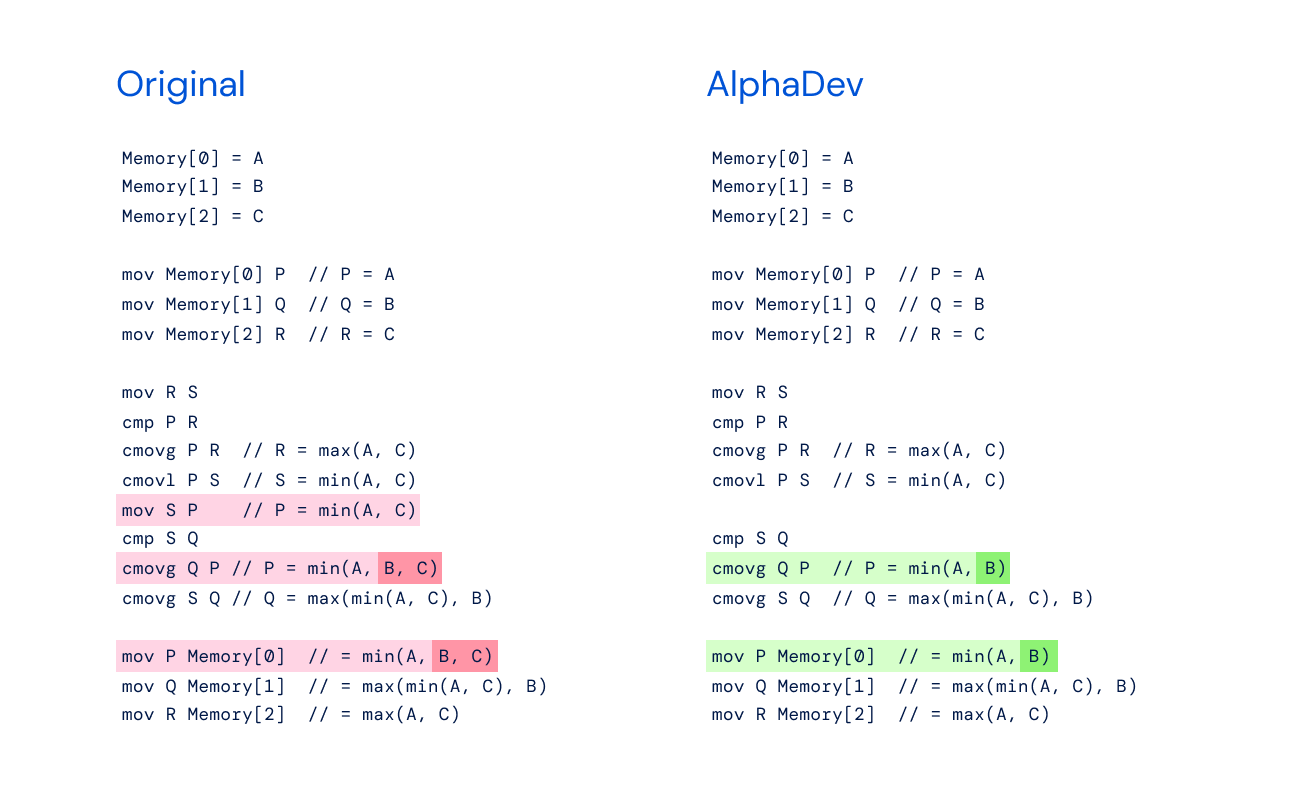
Google DeepMind 的全新强化学习系统 AlphaDev 发现了一种比以往更快的排序算法和哈希算法。这两者都是计算机科学领域中的基本算法,该算法成果已开源并将纳入到主要 C++ 库中供开发人员使用。「估计这次发现的排序和哈希算法每天会在全世界被调用数万亿次。」
现阶段 AlphaDev 探索新算法使用的语言是汇编指令。从头开始探索更快的算法,而不是基于现有算法之上。
Google DeepMind 认为这个层次存在许多改进的空间,而这些改进在更高级的编程语言中可能很难被发现。在这个层次上,计算机的存储和操作更加灵活,这意味着存在更多潜在的改进可能性,这些改进可能对速度和能源使用产生更大的影响。
「这只是 AI 提升代码效率进步的开始。」
现阶段大模型的知识落后问题
T5, GPT-3, PaLM, Flamingo 和 PaLI 等大型模型已经证明了在扩展到数百亿个参数并在大型文本和图像数据集上进行训练时存储大量知识的能力。这些模型在下游任务上实现了最先进的结果,例如图像字幕、视觉问答和开放式词汇识别。
尽管取得了这些成就,但这些模型需要大量的数据进行训练,最终会产生大量的参数(在许多情况下是数十亿个),从而导致大量的计算需求。
此外,用于训练这些模型的数据可能会过时,每次更新世界知识时都需要重新训练。例如,两年前训练的模型可能会产生有关现任美国总统的过时信息。
摘录翻译自 Google Blog